吉林大學(xué)計(jì)算機(jī)系統(tǒng)結(jié)構(gòu)第三章《指令級(jí)并行》課堂筆記(曲冠南老師版)
第三章 指令級(jí)并行 (Instruction-Level Parallelism, ILP)
3.1 基本概念
指令級(jí)并行(ILP) 是指單個(gè)處理器中,通過(guò)硬件或軟件技術(shù),同時(shí)執(zhí)行多條指令中不同操作的能力。其目標(biāo)是提高指令吞吐率,減少程序執(zhí)行時(shí)間。
核心思想:利用指令間的獨(dú)立性,通過(guò)流水線(Pipelining)、亂序執(zhí)行(Out-of-Order Execution, OoOE)、超標(biāo)量(Superscalar) 等技術(shù),讓處理器在一個(gè)時(shí)鐘周期內(nèi)發(fā)射和執(zhí)行多條指令。
關(guān)鍵限制:
- 數(shù)據(jù)相關(guān)(真相關(guān)):后續(xù)指令依賴于前面指令的結(jié)果。
- 名稱相關(guān):包括反相關(guān)和輸出相關(guān),可通過(guò)寄存器重命名解決。
- 控制相關(guān):由分支指令引起的依賴。
3.2 指令流水線的深入與冒險(xiǎn)
1. 流水線冒險(xiǎn) (Hazard)
- 結(jié)構(gòu)冒險(xiǎn):硬件資源沖突。解決方法:資源重復(fù)(如哈佛架構(gòu)分離指令/數(shù)據(jù)Cache,多端口寄存器文件)。
- 數(shù)據(jù)冒險(xiǎn):數(shù)據(jù)依賴導(dǎo)致無(wú)法獲得正確操作數(shù)。
- 寫(xiě)后讀 (RAW):真數(shù)據(jù)相關(guān),必須等待。可通過(guò)旁路/轉(zhuǎn)發(fā) (Forwarding/Bypassing) 技術(shù)緩解。
- 讀后寫(xiě) (WAR) 與 寫(xiě)后寫(xiě) (WAW):名稱相關(guān),可通過(guò)亂序執(zhí)行與寄存器重命名消除。
- 控制冒險(xiǎn):分支指令改變PC,導(dǎo)致預(yù)取的下游指令無(wú)效。
2. 提高流水線性能
- 增加流水線級(jí)數(shù)(加深流水線):提高主頻,但增加冒險(xiǎn)懲罰和復(fù)雜度。
- 提高流水線吞吐率:每個(gè)周期發(fā)射多條指令(超標(biāo)量、超長(zhǎng)指令字VLIW)。
3.3 動(dòng)態(tài)調(diào)度與亂序執(zhí)行
核心:記分牌算法 與 Tomasulo算法
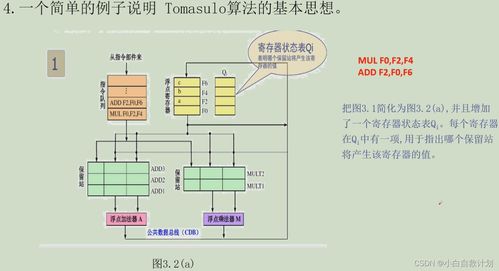
Tomasulo算法(曲老師重點(diǎn)講解)是動(dòng)態(tài)調(diào)度、實(shí)現(xiàn)亂序執(zhí)行的核心算法,尤其適合處理寄存器數(shù)量有限和長(zhǎng)延遲操作(如訪存、浮點(diǎn)運(yùn)算)。
核心組件與流程:
1. 保留站 (Reservation Stations):緩存已發(fā)射但未執(zhí)行的指令及其操作數(shù)(或指向操作數(shù)的標(biāo)簽)。
2. 公共數(shù)據(jù)總線 (CDB):用于將執(zhí)行完畢的結(jié)果廣播到所有需要該結(jié)果的保留站和寄存器文件。
3. 寄存器重命名:通過(guò)重排序緩沖 (ROB) 或保留站本身,將體系結(jié)構(gòu)寄存器映射到物理寄存器或標(biāo)簽,徹底消除WAR和WAW冒險(xiǎn)。
執(zhí)行階段:
- 發(fā)射 (Issue):指令順序發(fā)射到空閑保留站,并監(jiān)聽(tīng)操作數(shù)是否就緒。
- 執(zhí)行 (Execute):當(dāng)操作數(shù)全部就緒且功能單元空閑時(shí)開(kāi)始執(zhí)行(亂序)。
- 寫(xiě)回 (Write Result):通過(guò)CDB廣播結(jié)果。
3.4 分支預(yù)測(cè)
控制冒險(xiǎn)是限制ILP的主要瓶頸之一,現(xiàn)代處理器采用分支預(yù)測(cè)來(lái)推測(cè)執(zhí)行。
1. 靜態(tài)分支預(yù)測(cè):編譯器主導(dǎo)。
- 策略:預(yù)測(cè)永遠(yuǎn)不跳轉(zhuǎn)、永遠(yuǎn)跳轉(zhuǎn)、根據(jù)跳轉(zhuǎn)方向預(yù)測(cè)等。
2. 動(dòng)態(tài)分支預(yù)測(cè):硬件在運(yùn)行時(shí)根據(jù)歷史信息進(jìn)行預(yù)測(cè)。
- 分支歷史表 (BHT):用分支指令地址的低位索引一個(gè)表,表中記錄上一次該分支是否跳轉(zhuǎn)(1位預(yù)測(cè)器)。
- 兩位飽和計(jì)數(shù)器預(yù)測(cè)器:狀態(tài)機(jī)(00-不跳轉(zhuǎn),11-跳轉(zhuǎn)),只有連續(xù)兩次預(yù)測(cè)錯(cuò)誤才改變預(yù)測(cè)方向,抗干擾能力強(qiáng)。
- 相關(guān)(兩級(jí))分支預(yù)測(cè):利用其他分支的歷史結(jié)果來(lái)預(yù)測(cè)當(dāng)前分支(如GShare, Tournament Predictor)。
- 分支目標(biāo)緩沖 (BTB):緩存預(yù)測(cè)跳轉(zhuǎn)的分支的目標(biāo)地址,實(shí)現(xiàn)快速取指。
3.5 多發(fā)射處理器
1. 超標(biāo)量 (Superscalar)
- 硬件在運(yùn)行時(shí)動(dòng)態(tài)檢查指令間的依賴性,每個(gè)周期可發(fā)射可變數(shù)量的指令(如2-8條)。
- 代表:現(xiàn)代x86、ARM高性能核心。
- 關(guān)鍵挑戰(zhàn):依賴檢查邏輯復(fù)雜,隨著發(fā)射寬度增加,復(fù)雜度呈指數(shù)增長(zhǎng)。
2. 超長(zhǎng)指令字 (VLIW)
- 編譯器在編譯時(shí)靜態(tài)分析指令間的并行性,將多條可并行執(zhí)行的操作打包成一條很長(zhǎng)的指令(一個(gè)“包”)。
- 硬件簡(jiǎn)單,但依賴于智能編譯器,且二進(jìn)制代碼兼容性差。
- 代表:Intel Itanium (IA-64) 的EPIC架構(gòu)。
3.6 性能限制與ILP的未來(lái)
限制ILP的因素:
- 真實(shí)的數(shù)據(jù)依賴(程序固有的)
- 過(guò)程(函數(shù)調(diào)用)和分支
- 指令發(fā)射、執(zhí)行、提交的帶寬限制
- 存儲(chǔ)系統(tǒng)延遲(Cache Miss)
超越ILP的技術(shù):當(dāng)單線程ILP挖掘接近極限時(shí),計(jì)算機(jī)體系結(jié)構(gòu)轉(zhuǎn)向:
- 線程級(jí)并行 (TLP):同時(shí)多線程 (SMT)、多核 (Chip Multiprocessor)。
- 數(shù)據(jù)級(jí)并行 (DLP):SIMD指令擴(kuò)展(如SSE, AVX, Neon)。
- 請(qǐng)求級(jí)并行 (RLP):面向吞吐量計(jì)算,如GPU。
---
本章:指令級(jí)并行是現(xiàn)代高性能CPU設(shè)計(jì)的基石。從經(jīng)典的5級(jí)流水線出發(fā),通過(guò)動(dòng)態(tài)調(diào)度(Tomasulo)、分支預(yù)測(cè)、多發(fā)射(超標(biāo)量/VLIW)等一系列復(fù)雜技術(shù),盡可能地挖掘程序中的指令間并行性。ILP的收益存在遞減效應(yīng),這推動(dòng)了多核與異構(gòu)計(jì)算時(shí)代的到來(lái)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.x8xd4c.cn/product/57.html
更新時(shí)間:2026-02-24 11:00:38